
















- DAZ.online
- DAZ / AZ
- DAZ 32/2018
- Eindeutig uneindeutig
Foto: bestvc - stock.adobe.com
Diagnostik
Eindeutig uneindeutig?
Tests und ihre statistischen Tücken
„99%ige Sicherheit“ – klingt das nicht gut? Aus dem Blickwinkel der Test-Statistik kann das tatsächlich ein recht sicheres Ergebnis versprechen oder auch zu erbärmlich unklaren Resultaten führen. Woran liegt das?
Die meisten Tests sollen, im Vergleich zu Messungen mit einem quantitativen oder „halbquantitativen“ (mehr oder weniger grob gestuften) Resultat, eine Ja/Nein-Aussage treffen: Der Betreffende ist (nicht) HIV-positiv, schwanger oder hat (kein) Blut im Stuhl. Letztlich läuft dies auf eine Grenzwertprüfung hinaus: Es muss eine gewisse Anzahl an Viren (oder damit korrelierenden Sekundärprodukten wie z. B. Antikörper) vorhanden sein, oder ein gewisser Spiegel an Schwangerschaftshormon, Blut etc. Bereits hier lauern Unschärfen, und etliche Ergebnisse sind eben nicht so klar bzw. bedürfen weiterer Abklärung.
Falsch-positiv vs. falsch-negativ
Somit relativiert sich die trennscharfe Ja/Nein-Aussage oftmals zu einer schlichten Warnfunktion. Erst weitere Untersuchungen schaffen wirkliche Klarheit und zeigen Handlungskonsequenzen auf. Insoweit können viele Tests eher mit Warnleuchten im Auto verglichen werden: Ein ernster Schaden, z. B. fehlendes Kühlwasser oder Öl, sollte in Anbetracht der möglichen Konsequenzen zuverlässig detektiert werden. Dabei ist es am wichtigsten, wirklich jeden bedrohlichen Zustand anzuzeigen. Lieber akzeptiert man eine (gelegentliche) Fehlmeldung als ein Schweigen des Diagnosesystems bei einem ernsten Problem.
Aber das hat Grenzen: Wenn die Motorkontrollleuchte im Wochenrhythmus aufleuchtet, und es stellt sich immer wieder als Fehlalarm heraus, werden Sie sie irgendwann ignorieren, selbst bei berechtigter Warnung. Ähnlich ergeht es Alarmanlagen-Besitzern, die in erster Linie von Fehlalarmen geplagt werden. „Falsch-positive“ Meldungen sind also in gewissen Grenzen tolerabel, „falsch-negative“ sind jedoch hier ein absolutes „No-Go“.
Nun kann man das Ganze auch umdrehen: Das Diagnosesystem im Auto meldet beim Start „OK“. Hier wäre ein „falsch-positives“ Ergebnis (fälschlich OK gemeldet) nicht tolerabel; ein „falsch-negatives“ hingegen in einem engen Rahmen schon. Ganz analog können wir auch bei Krankheiten und deren Testung vier Fallunterscheidungen treffen (siehe Kasten).
Fallunterscheidungen
1. Der Patient ist tatsächlich krank bzw. infiziert. Dann gibt es zwei Möglichkeiten:
- a) Der Test detektiert die Krankheit / Infektion richtigerweise (richtig-positiv).
- b) Der Test detektiert die Krankheit / Infektion fälschlicherweise nicht (falsch-negativ, der möglichst zu vermeidende Fall).
2. Der Patient ist tatsächlich gesund bzw. ist nicht infiziert. Dann gibt es wieder zwei Möglichkeiten:
- a) Der Test detektiert die Krankheit / Infektion richtigerweise nicht (richtig-negativ).
- b) Der Test detektiert die Krankheit / Infektion fälschlicherweise (falsch-positiv).
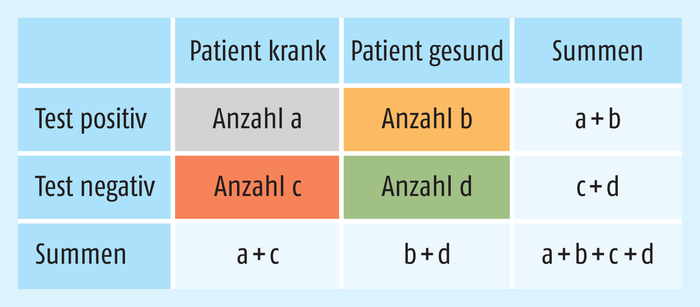
Diese vier Fälle lassen sich in einer Vierfeldertafel darstellen und mit konkreten Fallzahlen hinterlegen (Abb. 1).
Spezifität und Sensitivität
An dieser Stelle kommen die Begriffe Spezifität und Sensitivität als Kenngrößen ins Spiel. Die Spezifität ist der Anteil der richtig-negativ detektierten Fälle d / (b + d) aus der Gesamtheit der Gesunden b + d in der Vierfeldertafel: Jemand ist gesund und bekommt dies vom Test richtig angezeigt. Der zu 100% fehlende Anteil wird demzufolge falsch-positiv gemeldet – als krank beschrieben, obwohl gesund. Die Gefahr hier besteht darin, dass unnötige Therapien eingeleitet werden, die womöglich dem Patienten gar schaden. Minimiert wird dies durch Bestätigungstests (bei HIV die Regel) bzw. weitere Diagnoseverfahren.
Die Sensitivität ist der Anteil der richtig-positiv detektierten Fälle a / (a + c) aus der Gesamtheit der Kranken a + c: Jemand ist krank bzw. infiziert und bekommt dies vom Test richtig angezeigt. Der zu 100% fehlende Anteil wird demzufolge falsch-negativ gemeldet – als gesund beschrieben, obwohl krank und damit besonders kritisch und rot in der Vierfeldertafel hinterlegt. Die Gefahr liegt darin, dass nötige Therapien unterbleiben und im Falle von Infektionskrankheiten der Betreffende andere anstecken kann. Weil sich derjenige sicher fühlt, haben wir hier einen gefährlichen „blinden Fleck“.
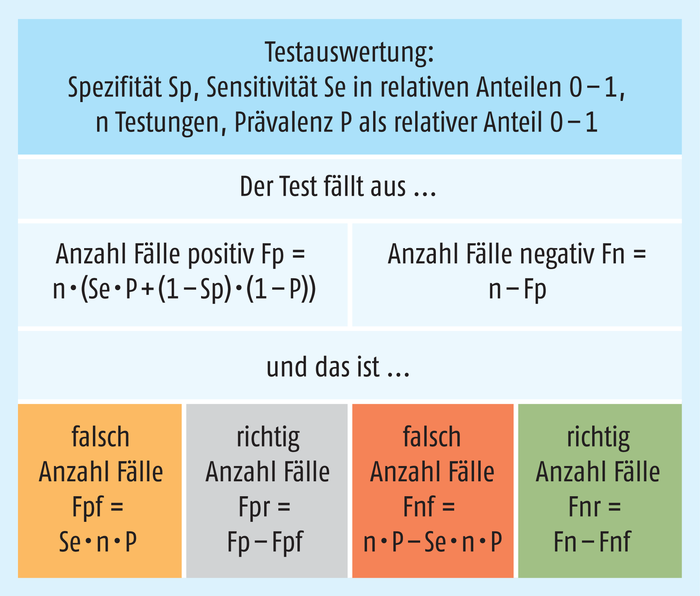
Da sich die Spezifität bzw. Sensitivität des Tests jeweils auf eine Untergruppe (die Gesunden oder Kranken) beziehen, jedoch die Gesamtzahl aus Gesunden und Kranken getestet wird, kommt die Prävalenz (die Häufigkeit der Krankheit bzw. Infektion in der getesteten Gruppe) als Einflussfaktor hinzu. Es ist also nicht egal, ob ein Merkmal bzw. eine Krankheit häufig oder selten in der getesteten Grundgesamtheit vorkommt. Betrachten wir deshalb einige Fälle näher, wobei sich die Auswertungsgrundlagen der Vierfeldertafel in Abb. 2 finden.
Was leisten HIV-Selbsttests?
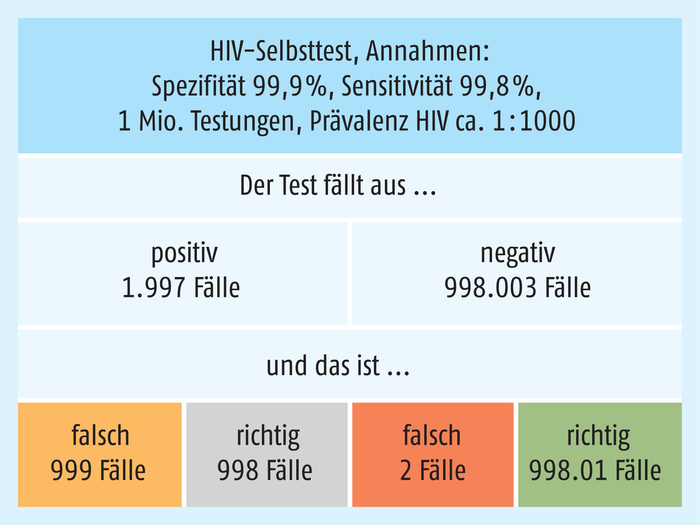
HIV-Selbsttests, wie sie bereits in anderen Ländern wie z. B. Frankreich zu haben sind, werden mit Werten für die Spezifität und Sensitivität von etwa 99,8 Prozent bis nahe 100 Prozent angegeben. In Abb. 3 wurden 99,9 Prozent für die Spezifität und 99,8 Prozent für die Sensitivität angenommen. Welche Ergebnisse wären zu erwarten, wenn wir von einer Prävalenz im Bereich von etwa 1 : 1000 ausgehen (bei rund 85.000 bekannten HIV-Infektionen hierzulande und jährlich gut 3000 Neuinfektionen eine realistische Annahme). Bewusst wird eine sehr große Zahl von 1 Million Testungen zugrundegelegt, um auch seltene Ergebnisse aufzuhellen.
Gerade einmal zwei Fälle würden falsch-negativ getestet werden, die gefährlichste Variante. Allerdings gäbe es eine ganze Menge „Fehlalarme“: Obwohl bei einem Vorkommen von 1 : 1000 nur 1000 positiv Getestete bei einem idealen Prüfverfahren zu erwarten wären, sind es bei dieser Testkonstellation und -qualität knapp 2000! Es kommt also auf einen richtig-positiv getesteten Patienten etwa ein weiterer, der fälschlich eine HIV-positiv-Diagnose erhält (oder anders gewendet: Wer positiv getestet wurde, ist nur mit etwa 50-prozentiger Wahrscheinlichkeit tatsächlich infiziert). Dies würde sich in einem präziseren, aufwendigeren Bestätigungstest ausräumen lassen. Das sind in diesem medizinischen Zusammenhang sicher noch akzeptable Relationen, die aber schon die Problematik zeigen – die der „Fehlalarme“ mit möglicherweise ganz erheblichen Konsequenzen für Mensch und auch Ökonomie.
Nehmen wir an, wir setzen einen Test mit den Daten wie beim HIV-Test für ein weitaus häufigeres Merkmal ein (oder wir testen gezielt nur Hochrisikogruppen auf HIV), bei einer Annahme der Prävalenz von 1 : 50 (= 2 Prozent) – was ändert das? Eine ganze Menge – wie in Abb. 4 dargestellt ist. Tatsächlich würden uns nun 40 Fälle (auf eine Million Tests) fälschlich-negativ „durchrutschen“. Allerdings verbessert sich das Verhältnis der richtigen-positiven zu den falsch-positiven Ergebnissen drastisch auf etwa 20 : 1. Nur rund einer von 20 positiv Getesteten ist ein Fehlalarm! Was für eine vertrackte Statistik …
Tests – was gibt es alles?
Die Spannbreite an Tests und Diagnostika ist unübersehbar groß geworden und zieht sich bis hin in die professionelle Labormedizin, Gendiagnostik und in die Kriminalistik (z. B. Drogentests, genetische Fingerabdrücke) hinein.
Der demgegenüber überschaubare Markt an käuflichen Selbsttests („Teststreifen“ bzw. teils weitaus komplexer aufgebaute Testkassetten) für die (Apotheken-)Kunden ist bislang wirtschaftlich nicht allzu erfolgreich, wenn man einmal vom Klassiker „Schwangerschaftstest“ absieht. Dennoch bietet der Markt (mit Anbietern wie Merck, NanoRepro, Roche, Stada u. a.) einiges an Auswahl, hier einige Beispiele:
- Basierend auf Kapillarblut die diversen klassischen Blutparameter, aber auch Eisen-, Vitamin- und Mineralstoffspiegel, mögliche Allergiedisposition durch orientierenden Nachweis von entsprechendem Ig E gegenüber häufigen Pollen, Tierhaaren, Hausstaub, Gluten, Ei, diversen anderen Nahrungsmitteln, Test auf Helicobacter pylori-Antigene, demnächst auch HIV im Selbsttest u. a. m.,
- Harntests, von den klassischen „Harnteststreifen“ über Schwangerschafts- und Ovulationstests, Prüfung auf Beginn der Menopause bis hin zum Test auf illegale Drogen,
- Nachweis von okkultem Blut im Stuhl,
- männliche Zeugungsfähigkeit aus dem Ejakulat.
Meist wird im Sinne einer Ja/Nein-Aussage getestet, teils werden (halb-)quantitative Messergebnisse geliefert. Unsere statistischen Erläuterungen haben die Ja/Nein-Aussage im Blick.
Für den künftigen Apothekenalltag könnten pharmakogenetische Tests auf Medikamentenverträglichkeit und -wirksamkeit eine größere Bedeutung erlangen. Obwohl bereits seit Jahren auf dem Markt (z. B. Humatrix), ist eine größere Durchdringung bislang ausgeblieben, obwohl der Nutzen im Einzelfall für den Patienten wie auch Kostenträger unbestritten ist, lassen sich doch Unwirksamkeit oder erforderliche Dosisanpassungen bei vielen, auch lange etablierten und bekannten Wirkstoffen bereits im Vorhinein bestimmen. Diese Tests werden freilich im Labor durchgeführt und sind nicht für den Heimgebrauch.
Das gilt auch für die hochspannenden, nicht unumstrittenen Gentests (typischerweise auf einer Speichelprobe beruhend) für eine ganze Reihe von Krankheitsrisiken, wie sie insbesondere in den USA kommerziell für das breite Publikum angeboten werden.
Das führt schnell zu ethischen Dimensionen so mancher Tests: Ist Wissen immer ein Vorteil? Ist insbesondere das Wissen um eine drohende schwere Krankheit, für die es nur unzureichende Therapieoptionen gibt, wirklich ein Gewinn für den Betreffenden? Zumal auch hier wieder nur mit Statistik und Wahrscheinlichkeiten operiert werden kann. Das Gendiagnostikgesetz (GenDG) setzt demzufolge hierzulande einen recht engen rechtlichen Rahmen.
Zukünftige Tests benötigen hohe Treffsicherheit
Treiben wir das Spiel mit den großen Zahlen weiter. Manch einer träumt bereits davon, dass es eines Tages selbstverständlich sein wird, den Finger auf das Smartphone zu legen (auf ein spezielles Mikroneedle-Feld) und z. B. eine Krebs-Vorhersage zu bekommen, weil das Gerät in der Lage ist, gewisse Biomarker zu identifizieren. Man verkauft Ihnen das dann z. B. mit „98- bis 99-prozentiger Sicherheit“, wobei damit 99-prozentige Spezifität und 98-prozentige Sensitivität gemeint seien. Das klingt doch sehr hoffnungsvoll, oder?
Schauen wir mit dem statistischen Adlerblick näher hin (Abb. 5a): Die getesteten Krebsarten sollen wieder eine Prävalenz von 1 : 1000 bezogen auf die Gesamtbevölkerung haben (angesichts der vielen verschiedenen Krebsarten gilt das bereits nur für die häufigeren). Bei einer Million solcher Tests würden 20 Pechvögel mit ihrem Krebs übersehen werden. 980 würden richtig erkannt. Doch das dicke Ende naht: Fast 10.000 Fehlalarme – zehnmal so viele wie zutreffende Diagnosen! Die Praxen würden gestürmt, teure Folgeuntersuchungen wären die Folge, und manch einer würde womöglich fälschlich unter dem Messer oder der Strahlenkanone landen oder am Tropf einer Zytostatika-Behandlung hängen. 98 oder 99 Prozent klingen auf den ersten Blick gut, wären hier aber eine Katastrophe. Dies illustriert, vor welchen Herausforderungen die „Predictive Analytics“ noch stehen. Diese Verfahren benötigen eine extrem hohe Treffsicherheit, wenn sie in der Breite angewendet werden sollen.
Weitaus verbessern würde sich die Situation wiederum, wenn man nicht Jedermann, sondern nur Risikogruppen testet, wie in Abb. 5b zu sehen. Die Prävalenz in der Risikogruppe (z. B. schlicht Ältere, Raucher etc.) sei 1 : 100 (1 Prozent). Dann kommt auf eine zutreffende Positiv-Testung „nur“ noch ein Fehlalarm, allerdings werden 200 Kranke bei einer Million Tests übersehen.
Fazit
Dieser kleine Ausflug in die Welt der Statistik zeigt, dass viele Tests durchaus kritisch zu sehen sind. Nicht wenige Testungen (Biomarker!) oder Diagnoseverfahren weisen heute noch Spezifitäts- und Sensitivitätswerte von unter 90 Prozent auf. Je nach Konstellation läuft das bisweilen auf ein regelrechtes „Diagnose-Lotto“ hinaus.
Aber selbst bei hoher „Treffsicherheit“ gilt, dass dies alles nur unter Idealbedingungen einer sorgfältigen Einhaltung der vorgeschriebenen Testbedingungen funktioniert. Einige Tests sind wesentlich robuster als andere. Weitere Einschränkungen beziehen sich auf Nachweisgrenzen und daraus resultierende „Zeitfenster“ (ab wann und bis wann kann ein Test überhaupt brauchbare Ergebnisse liefern, Schwangerschafts- und HIV-Tests als prominente Beispiele), und was wird überhaupt nachgewiesen. Bei HIV-Tests ist das z. B. die Frage nach den überhaupt erfassten Subtypen der HIV-Viren (die lokal sehr unterschiedlich verbreitet sind). Dies kann die Aussagekraft der einzelnen Tests massiv beeinträchtigen.
Selbst über lange etablierte Testverfahren lässt sich unter diesen statistischen Aspekten trefflich diskutieren – erwähnt seien nur der umstrittene PSA-Test (PSA = prostataspezifisches Antigen) oder die Mammografie bei der Brustkrebsvorsorge. Bei letzterer kommt zusätzlich zu den statistischen Erwägungen ein mögliches Strahlenrisiko auf der Negativseite hinzu, sodass noch zusätzlich zum reinen Aussagewert eine Nutzen-Risiko-Abwägung zu treffen ist.
Vermeintlich schöne Zahlen, unsauber definiert („99 Prozent Sicherheit“) entpuppen sich gerade in der Welt der Tests schnell als Blendwerk, welches durch nüchterne statistische Betrachtungen entzaubert wird. Neben der Tatsache, dass tatsächliche Krankheiten bzw. Infektionen „übersehen“ werden, kann bisweilen auch ein zu empfindliches Ansprechen umgekehrt ein nicht mehr sinnvolles Maß an „Fehlalarmen“ produzieren. Dies ist von Fall zu Fall sorgfältig abzuwägen. Das mag auch erklären, weswegen z. B. der Gesetzgeber lange gezögert und abgewogen hat, bevor er die HIV-Tests nunmehr für den Kundengebrauch freigibt. |
Eine Excel-Datei zu diesem Thema kann gerne beim Autor per E-Mail angefordert werden.



0 Kommentare
Das Kommentieren ist aktuell nicht möglich.