















- DAZ.online
- DAZ / AZ
- DAZ 5/2016
- OR, RR, NNT
Foto: yahyaikiz - Fotolia.com
Klinische Studien
OR, RR, NNT
Grundlagen der medizinischen Statistik: Klinische Studien und ihre Bewertung, Teil 3
Studiendaten mit Niveau
In klinischen Studien werden die interessierenden Daten zu verschiedenen Zeitpunkten gesammelt (s. Teil 2 dieser Serie). Zu Beginn werden die Basischarakteristika der Probanden (z. B. Geschlecht, Alter, Komedikation, Krankheitsstadium) dokumentiert. Im weiteren Verlauf bis zum Ende der Studie werden zu definierten Zeitpunkten die absoluten Daten für die primären und sekundären Endpunkte erhoben und in einer zuvor festgelegten Zielvariable ausgedrückt. In welcher Art und Weise diese Daten ausgewertet werden, hängt in erster Linie von der Art der Daten und dem Studientyp ab. So unterscheidet man bei den erhobenen Daten zwischen unterschiedlichen Messniveaus (s. Tab. 1) [1, 2].
Bezeichnung |
Beschreibung |
Beispiele |
|---|---|---|
binär, dichotom |
Entweder-oder-Fragen (Antwort: ja oder nein) |
|
nominal |
qualitative, aber ungeordnete (und neutrale) Kategorien |
|
ordinal |
qualitative und geordnete (d. h. graduelle) Kategorien |
|
stetig, kontinuierlich |
quantitativ messbare Merkmale und Messwerte (Maßeinheit) |
|
Effektmaße: Rechnen anhand der Vierfeldertafel
Bei Zielvariablen mit binärem Messniveau (Ereignis aufgetreten? ja oder nein?) wird deren absolute Häufigkeit – also die Anzahl des Auftretens bzw. Nicht-Auftretens in den beiden Studiengruppen – in einer sogenannten Vierfeldertafel (auch: 2 × 2-Tafel oder Kontingenztafel) dargestellt (s. Kasten). Die Vierfeldertafel kann in Beobachtungsstudien und Interventionsstudien angewendet werden [3, 4]. Hier zwei Beispiele für eine Exposition bzw. Intervention und das Ereignis:
- in einer Kohortenstudie: „Rauchen“ und „Lungenkarzinom aufgetreten?“,
- in einer Interventionsstudie: „Anwendung eines neuen oralen Antidiabetikums“ und „Ziel-HbA1c erreicht?“.
Gruppe |
Ereignis eingetreten? |
Summe |
|
|---|---|---|---|
ja |
nein |
||
Exposition,Intervention |
a |
b |
a + b |
Nicht-Exposition,Kontrolle |
c |
d |
c + d |
|
absolutes Risiko, dass in der exponierten Gruppe das Ereignis eintritt: ARexp = a ÷ (a + b)
absolutes Risiko, dass in der nicht-exponierten Gruppe das Ereignis eintritt: ARnicht-exp = c ÷ (c + d)
relatives Risiko (Vergleich zwischen beiden Gruppen): RR = ARexp ÷ ARnicht-exp
absolute Risikoreduktion: ARR = ARnicht-exp - ARexp
relative Risikoreduktion: RRR = 1 - RR
Odds Ratio (Chancenverhältnis): OR = a × d ÷ b × c
Number needed to treat (so viele Patienten müssen behandelt werden, um ein Ereignis zu vermeiden): NNT = 1 ÷ ARR
| |||
Gruppe |
Herzinfarkt in 5 Jahren? |
Summe |
|
|---|---|---|---|
ja |
nein |
||
Neues orales Antidiabetikum |
160 |
1840 |
2000 |
Standardtherapie (Kontrolle) |
200 |
1800 |
2000 |
|
RR = (160 ÷ 2000) ÷ (200 ÷ 2000) = 0,08 ÷ 0,1 = 0,8 oder 80%
RRR = 1 - 0,8 = 0,2 oder 20%
ARR = (200 ÷ 2000) - (160 ÷ 2000) = 0,10 - 0,08 = 0,02 oder 2%
NNT = 1 ÷ 0,02 = 50
| |||
Häufige Abkürzungen
AR: absolutes Risiko
RR: relatives Risiko
ARR: absolute Risikoreduktion
RRR: relative Risikoreduktion
OR: Odds Ratio, Chancenverhältnis
KI: Konfidenzintervall, Vertrauensbereich
NNT: Number needed to treat
Aus der absoluten Häufigkeit, mit der das jeweilige Ereignis in den einzelnen Gruppen auftritt, kann die Wahrscheinlichkeit des absoluten Auftretens in der Population abgeschätzt werden. In der Terminologie klinischer Studien wird in der Regel von Risiken oder Chancen gesprochen, unabhängig davon, ob das Ereignis für den Patienten positiv („Ziel-HbA1c erreicht“) oder negativ ist („Lungenkarzinom aufgetreten“) [4].
Diese und andere Wahrscheinlichkeiten werden Effektmaße genannt, weil sie die Stärke oder Größe eines Effekts quantitativ angeben [2]. Geläufige Effektmaße zum Vergleich von zwei Gruppen sind beispielsweise das relative Risiko (RR), die absolute und relative Risikoreduktion (ARR, RRR), das Odds Ratio (OR, Chancenverhältnis) und die Number needed to treat (NNT).
Mit welchem Effektmaß ein Studienergebnis sinnvoll dargestellt werden kann, hängt vom Studientyp und -design ab (Tab. 2) [3, 5 – 7]. Die Relativmaße wie RR oder OR vergleichen die Wahrscheinlichkeit (oder Risiko bzw. Chance), dass ein Ereignis auftritt, in den beiden Studiengruppen. In einer randomisierten kontrollierten Studie, in der die Zielvariable beispielsweise in dem Auftreten eines unerwünschtes Ereignisses besteht, bedeutet ein RR < 1, dass die Behandlung in der Verumgruppe besser ist als in der Kontrollgruppe.
Ergänzend sei erwähnt, dass mithilfe von epidemiologischen Studien die Häufigkeit von Erkrankungen oder anderen Ereignissen in einer Population errechnet werden kann, und zwar
- die Inzidenz (Anzahl der Neuerkrankungen in einem Zeitraum) und
- die Prävalenz (Anzahl der Erkrankungen zu einem bestimmten Zeitpunkt). StudientypStudienpopulation und DatenerhebungEffektmaßQuerschnittsstudieMomentaufnahme anhand einer repräsentativen Stichprobe der PopulationPrävalenzFall-Kontroll-StudieVergleich: Fälle (Kranke) vs. Kontrolle (Gesunde), meist retrospektivORKohortenstudieVergleich: Exponierte vs. Nicht-Exponierte, meist prospektivInzidenz(rate),RRInterventionsstudieTherapiestudie: Verum vs. Kontrolle, prospektivOR, RR, ARR, RRR, NNT
Wie groß ist der Nutzen einer neuen Therapie?
Zur weiteren Veranschaulichung ist als Beispiel einer Vierfeldertafel das Ergebnis einer hypothetischen randomisierten kontrollierten Studie (RCT) aufgezeigt: 4000 Typ-2-Diabetiker wurden fünf Jahre lang entweder mit einem neuen oralen Antidiabetikum (Verumgruppe) oder mit der Standardtherapie (Kontrollgruppe) behandelt. Als primärer Endpunkt wurde das Auftreten eines Herzinfarkts innerhalb dieses Zeitraums gewählt. In der Verumgruppe traten insgesamt 160 Herzinfarkte bei 2000 Probanden auf, in der gleich großen Kontrollgruppe hingegen 200 Herzinfarkte. Hieraus errechnet sich ein RR von 80 Prozent, d. h. dass in der Verumgruppe das Risiko, einen Herzinfarkt zu erleiden, um 20 Prozent reduziert war (RRR = 20%), was eine beachtliche Verbesserung der Prognose in der Verumgruppe vermuten lässt. Die absolute Risikoreduktion (ARR) betrug jedoch nur zwei Prozent. Oder anhand der NNT ausgedrückt: 50 Patienten müssen fünf Jahre lang mit dem neuen oralen Antidiabetikum anstatt mit der Standardtherapie behandelt werden, um einen einzigen Herzinfarkt zu vermeiden.
An diesem Beispiel lässt sich sehr gut zeigen, dass man mit Relativgrößen wie dem RR und der RRR eindrucksvolle Wirksamkeitseffekte darstellen kann, obwohl sie über die absoluten Risiken in den einzelnen Gruppen nichts aussagen. Der Nutzen für den einzelnen Patienten zeigt sich erst, wenn zusätzlich die ARR oder die NNT angegeben wird [3, 4, 7].
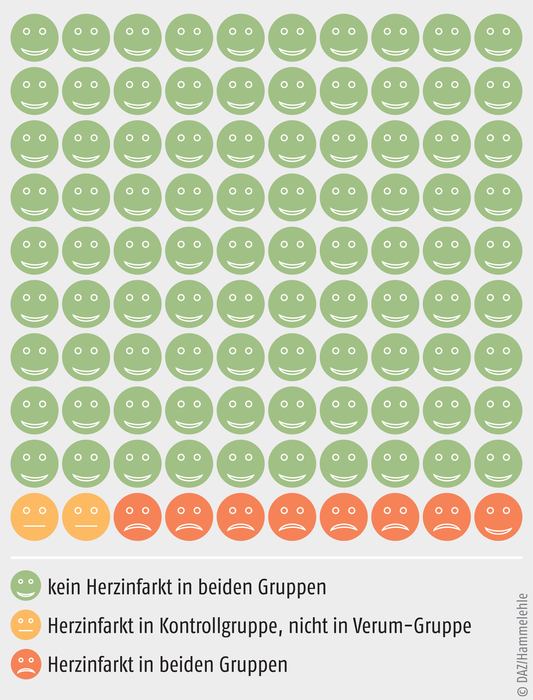
Den Nutzen der Therapie mit dem neuen oralen Antidiabetikum im Vergleich zur Standardtherapie kann man auch grafisch verdeutlichen (Abb. 1) [11]: Aufgrund der ARR von zwei Prozent bietet das neue Arzneimittel 98 von 100 behandelten Patienten keinen Vorteil bezüglich des Herzinfarktrisikos (grüne und rote Köpfe in Abb. 1). Bei der Entscheidung für oder gegen das neue Medikament muss dessen Nutzen gegen seine möglichen Nebenwirkungen und höheren Therapiekosten abgewogen werden [12].
Abb. 1: Ergebnis einer klinischen Studie: Prüfung eines neuen oralen Antidiabetikums gegen die Standardmedikation bei Diabetikern (Verumgruppe und Kontrollgruppe jeweils: n = 100). Endpunkt: Herzinfarkt innerhalb von fünf Jahren. Für 98 Patienten der Verumgruppe ergibt sich demnach kein Vorteil im Vergleich zu einer Behandlung mit der Standardmedikation (Grafik nach Chris Cates [11]).
Handelt es sich bei einem Endpunkt nicht um binäre, sondern um stetige Daten (z. B. die mittlere Senkung des systolischen Blutdrucks), wird als Effektmaß oft die Differenz der Mittelwerte der Interventionsgruppe und der Kontrollgruppe herangezogen.
Odds Ratio
Alternativ zum RR kann das OR oder Chancenverhältnis als Effektmaß in Beobachtungs- und Interventionsstudien angegeben werden. Das OR kann als Näherungswert für das RR verstanden werden, wenn die absoluten Risiken in beiden Gruppen klein sind (1 – 5%). In Fall-Kontroll-Studien ist prinzipiell nur die Angabe eines OR zulässig, da die ausgewählten Fälle und Kontrollen vorher vom Untersucher festgelegt werden und nicht aus derselben Grundgesamtheit stammen. Insofern gibt es kein RR [3].
Signifikanztests – die Auswahl ist entscheidend
Um die Effekte verschiedener Therapien in zwei oder mehreren Studiengruppen statistisch zu vergleichen, verwendet die medizinische Forschung statistische Tests oder Signifikanztests. Welcher Test für die jeweilige Studie am besten geeignet ist, richtet sich dabei nach folgenden Kriterien [1, 9, 10]:
- Stichprobenzahl: Wird nur innerhalb einer Gruppe (vorher/nachher) oder werden verschiedene Gruppen (zwei oder mehr) miteinander verglichen?
- Handelt es sich um abhängige oder unabhängige Stichproben? Bei einem Parallelgruppendesign liegen unabhängige, bei Cross-over-Studien hingegen abhängige Stichproben vor, da hier alle Probanden die zu vergleichenden Therapien erhalten.
- Welches Messniveau weisen die Studiendaten auf (s. Tab. 1)?
- Bei stetigen Daten: Sind diese normalverteilt?
- Kann die Intervention den Messwert (z. B. Cholesterolspiegel) voraussichtlich nur positiv oder auch negativ verändern? Davon hängt es ab, ob man einen ein- oder zweiseitigen Test anwenden muss.
Obwohl eine Vielzahl an statistischen Tests zur Verfügung steht, wird in der klinischen Forschung nur etwa ein Dutzend häufig angewendet, wie z. B. der Student-t-Test bei stetigen, normalverteilten Daten sowie der Exakte Test nach Fisher oder der Chi-Quadrat-Test bei binären Daten. Die Wahl eines inadäquaten Tests kann dazu führen, dass die Signifikanz der Ergebnisse völlig falsch eingeschätzt wird und die daraus gezogenen Schlussfolgerungen nicht korrekt sind. Hier sei auf die einschlägige Literatur zur medizinischen Statistik verwiesen (z. B. [1, 9, 10]).
Zufall oder nicht? Interpretation des p-Werts
Bei der Planung einer Studie stellen die Untersucher eine sogenannte Nullhypothese auf. In der Regel wird hierbei von der Gleichheit des Effekts von z. B. Intervention und Kontrolle ausgegangen. Die Alternativhypothese lautet dementsprechend, dass ein Unterschied besteht. Es liegt in der Natur jedes Experiments wie auch einer klinischen Studie, dass man sich bei der Datenerhebung irren kann und fälschlicherweise annimmt, dass die Alternativhypothese richtig ist. Diese Irrtumswahrscheinlichkeit nennt man Signifikanzniveau α (= Fehler 1. Art). Bei der Planung klinischer Studien setzt man fest, welche Irrtumswahrscheinlichkeit akzeptabel ist. In den meisten Fällen wird α = 0,05 (= 5%) gewählt, manchmal auch α = 0,01 (= 1%).
Der p-Wert ist das Ergebnis eines Signifikanztests und drückt die Wahrscheinlichkeit aus, dass die Nullhypothese richtig ist. Bei einem p-Wert < 0,05 (also kleiner als das Signifikanzniveau α) spricht man von einem statistisch signifikanten Ergebnis, denn die Wahrscheinlichkeit, dass ein gefundener Unterschied zwischen Intervention und Kontrolle rein zufällig entstanden ist, ist gering. Im Umkehrschluss bedeutet dies, dass mit hoher Wahrscheinlichkeit ein Effektunterschied besteht [13, 14].
Da der p-Wert nur ausdrückt, ob ein gefundener Unterschied statistisch signifikant ist oder nicht, kann man aus ihm nicht ableiten, wie groß oder in welche Richtung der Unterschied ausfällt.
Bereich des Vertrauens – das Konfidenzintervall
Wurde in einer klinischen Studie der Effekt der Intervention errechnet, so kann dieser Wert nicht auf die Realität (Gesamtpopulation) übertragen werden. Der wahre Effekt liegt in einem gewissen Bereich ober- und unterhalb des errechneten Wertes, dem Konfidenzintervall. In der Regel wird in klinischen Studien ein 95-prozentiges Konfidenzintervall (95%-KI) angegeben, das diejenigen 95 Prozent der Messwerte umfasst, die dem Mittelwert am nächsten sind, und die übrigen, extremsten Werte ignoriert [13, 15].
Beträgt beispielsweise die Differenz der mittleren systolischen Blutdrucksenkung eines Medikaments A gegenüber Medikament B im Mittel -4 mmHg mit einem 95%-KI von -2 bis -7 mmHg, so liegt die Differenz in der Gesamtpopulation mit hoher Wahrscheinlichkeit ebenfalls in diesem Bereich. Grundsätzlich gilt: Je größer die Studiengruppen sind, desto schmaler wird das Konfidenzintervall.
Mit dem Konfidenzintervall kann man nicht nur den realen Effekt einer Intervention einschätzen, sondern auch eine statistische Signifikanz ableiten:
- Wird als Effektmaß eine Differenz von Werten aus zwei Gruppen gewählt, so bedeutet ein 95%-KI, das die 0 miteinschließt: kein signifikanter Unterschied zwischen den beiden Gruppen. Ein konkretes Beispiel dazu zeigt die Tabelle 3 [16].
- Bei Effektmaßen, die durch Division errechnet werden (RR, OR), bedeutet hingegen ein 95%-KI, das den Wert 1 miteinschließt (z. B. 0,9 bis 1,2), einen nicht-signifikanten Unterschied [13, 15].
ZielvariableVerumgruppeKontrollgruppep-Wert95%-KI
Temperaturänderung (Δ T) 0 – 4 h-1,12 ± 0,92 °C-1,38 ± 0,84 °C0,08-0,49 bis 0,02 °C
Merke: Eine statistische Signifikanz ist nicht mit klinischer Relevanz gleichzusetzen. So können bei sehr groß angelegten Studien mit vielen Teilnehmern auch sehr kleine Effektunterschiede zwischen den Gruppen gezeigt werden. Ob diese Unterschiede klinisch relevant sind, muss jedoch hinterfragt werden (in diesem Beispiel: Verringert eine statistisch signifikante Blutdrucksenkung von 4 mmHg die Mortalität?).
Zusammenfassung
Wichtige Effektmaße zur Darstellung von binären Variablen in Interventionsstudien sind das relative Risiko und das Odds Ratio. Zur besseren Einschätzung des patientenindividuellen Nutzens ist jedoch auch die Angabe der absoluten Risiken und der Number needed to treat notwendig. Statistisch signifikante Unterschiede zwischen den Behandlungsgruppen erkennt man an einem p-Wert < 0,05, dessen Aussagekraft mit der zusätzlichen Angabe des 95%-Konfidenzintervall erhöht wird. Eine statistische Signifikanz ist jedoch nicht mit der klinischen Relevanz gleichzusetzen. |
Die vorherigen Folgen dieser Serie
1: Die Auswahl des richtigen Studientyps. DAZ 2016, Nr. 2, S. 56 – 61
2: Goldstandard: Randomisierte kontrollierte Studien. DAZ 2016, Nr. 3, S. 58 – 62
Literatur
[1] Bender R et al. Wichtige Signifikanztests. Dtsch Med Wochenschr 2007;132:e24-e25
[2] EbM-Glossar, Stand Oktober 2011; www.ebm-netzwerk.de/was-ist-ebm/images/dnebm-glossar-2011.pdf
[3] Sauerbrei W, Blettner M. Interpretation der Ergebnisse von 2×2-Tafeln. Dtsch Ärztebl Int 2009;106(48):795-800
[4] Bender R, Lange S. Die Vierfeldertafel. Dtsch Med Wochenschr 2007;132:e12-e14
[5] Klug S et al. Wichtige epidemiologische Studientypen. Dtsch Med Wochenschr 2007;132:e45-e47
[6] Ressing M et al. Auswertung epidemiologischer Studien. Dtsch Ärztebl Int 2010;107(11):187-92
[7] Schechtman E. Odds Ratio, Relative Risk, Absolute Risk Reduction, and the Number Needed to Treat – Which of These Should We Use? Value Health 2002;5(5):431-36
[8] Lange S, Bender R. Was ist ein Signifikanztest? Allgemeine Aspekte. Dtsch Med Wochenschr 2007;132:e19-e21
[9] du Prel JB et al. Auswahl statistischer Testverfahren. Dtsch Ärztebl Int 2010;107(19):343-8
[10] Greenhalgh T. Einführung in die evidenzbasierte Medizin, 3. Auflage, Verlag Hans Huber, Bern 2015
[11] Cates C. EBM Web Site, Visual Rx; www.nntonline.net/visualrx
[12] Stiggelbout AM et al. Shared decision making: really putting patients at the centre of healthcare. BMJ 2012;344:e256
[13] du Prel JB et al. Konfidenzintervall oder p-Wert? Dtsch Ärztebl 2009;106(19):335-339
[14] Bender R, Lange S. Was ist der p-Wert? Dtsch Med Wochenschr 2007;132:e15-e16
[15] Bender R, Lange S. Was ist ein Konfidenzintervall?. Dtsch Med Wochenschr 2007;132:e17-e18
[16] Kim C-K et al. Dexibuprofen for fever in children with upper respiratory tract infection. Pediatrics Int 2013;55:443-449
Autorinnen
Dr. Mirjam Gnadt arbeitet als Krankenhausapothekerin im Universitätsklinikum Erlangen und leitet die dort ansässige Arzneimittelinformationsstelle der Bayerischen Landesapothekerkammer.
Monika Dircks arbeitet seit 2006 als Krankenhausapothekerin, zurzeit als Stationsapothekerin in der Strahlen- und Frauenklinik des Universitätsklinikums Erlangen.



0 Kommentare
Das Kommentieren ist aktuell nicht möglich.